Zhuowan Li (李卓婉)
I am a software engineer at Google Deepmind. I am currently working on Gemini post-training, with a focus on personalization and open-ended questions.
I finished my Ph.D. in Feb 2024 from Johns Hopkins University, co-advised by Prof. Alan Yuille and Benjamin Van Durme. I am a member of the CCVL lab. I received my B.E. degree from Tsinghua Univeristy in 2018, where I double major in Electronic Engineering and Journalism and Communication. I have also interned at Amazon AWS, Meta AI, Adobe Research and Sensetime.
In part time, I am a big fan of outdoor sports including rock climbing, snowboarding, skiing, hiking, mountaineering, etc. I am learning tennis recently.
CV /
Google Scholar /
Twitter /
Github
|

Email: lizhuowan14 at gmail dot com
|
|
News
[Nov 2024] I will attend EMNLP 2024 in person at Miami. Happy to connect!
[June 2024] I will attend CVPR 2024 in person at Seattle. Happy to chat!
[Feb 2024] I graduated from JHU and joined Google as a software engineer!
[June 2023] I will attend CVPR 2023 in person at Vancouver. Let me know if you want to talk with me!
[May 2023] Started as as applied scentist intern at Amazon AWS.
[May 2023] Invited talk at the Computational Cognitive Science Lab at MIT.
[February 2023] Super-CLEVR is accepted by CVPR 2023 as Highlight.
Last updated: 2025/08/12.
|

|
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities
Gemini Team, Google
Technical Report, 2025
arXiv
|
|
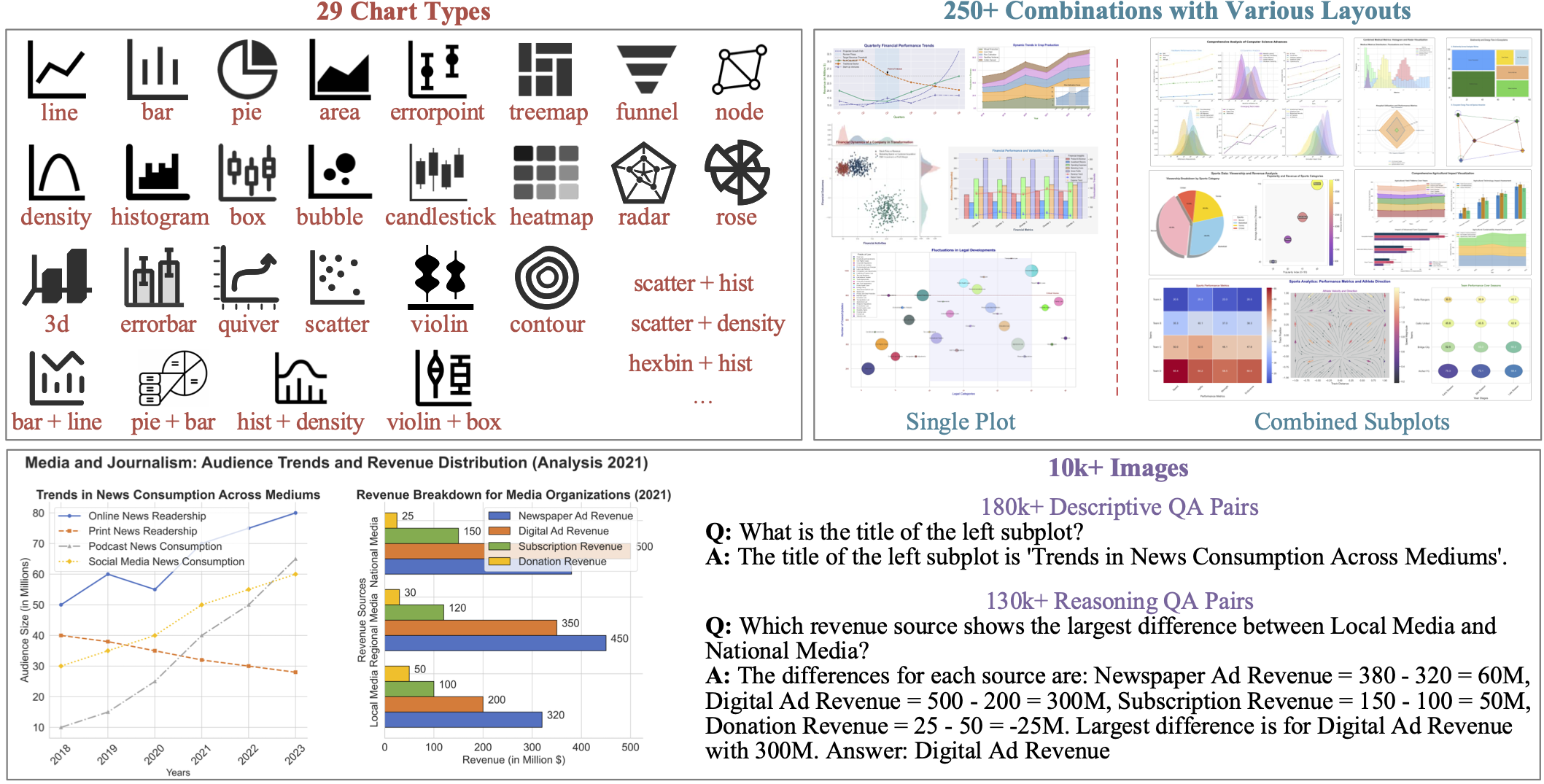
Effective Training Data Synthesis for Improving MLLM Chart Understanding
Yuwei Yang, Zeyu Zhang, Yunzhong Hou, Zhuowan Li, Gaowen Liu, Ali Payani, Yuan-Sen Ting,
Liang Zheng
ICCV, 2025
arXiv
|
|
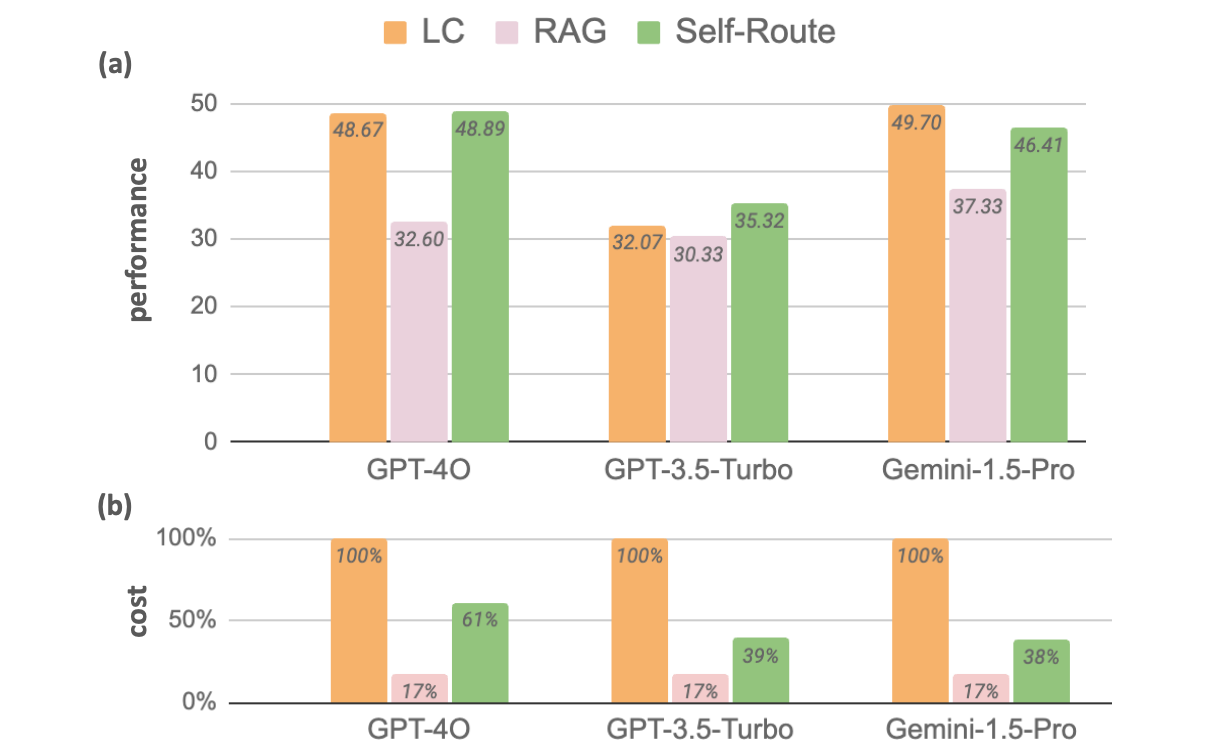
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Zhuowan Li,
Cheng Li,
Mingyang Zhang,
Qiaozhu Mei,
Michael Bendersky
EMNLP Industry Track, 2024
arXiv /
poster
|
|
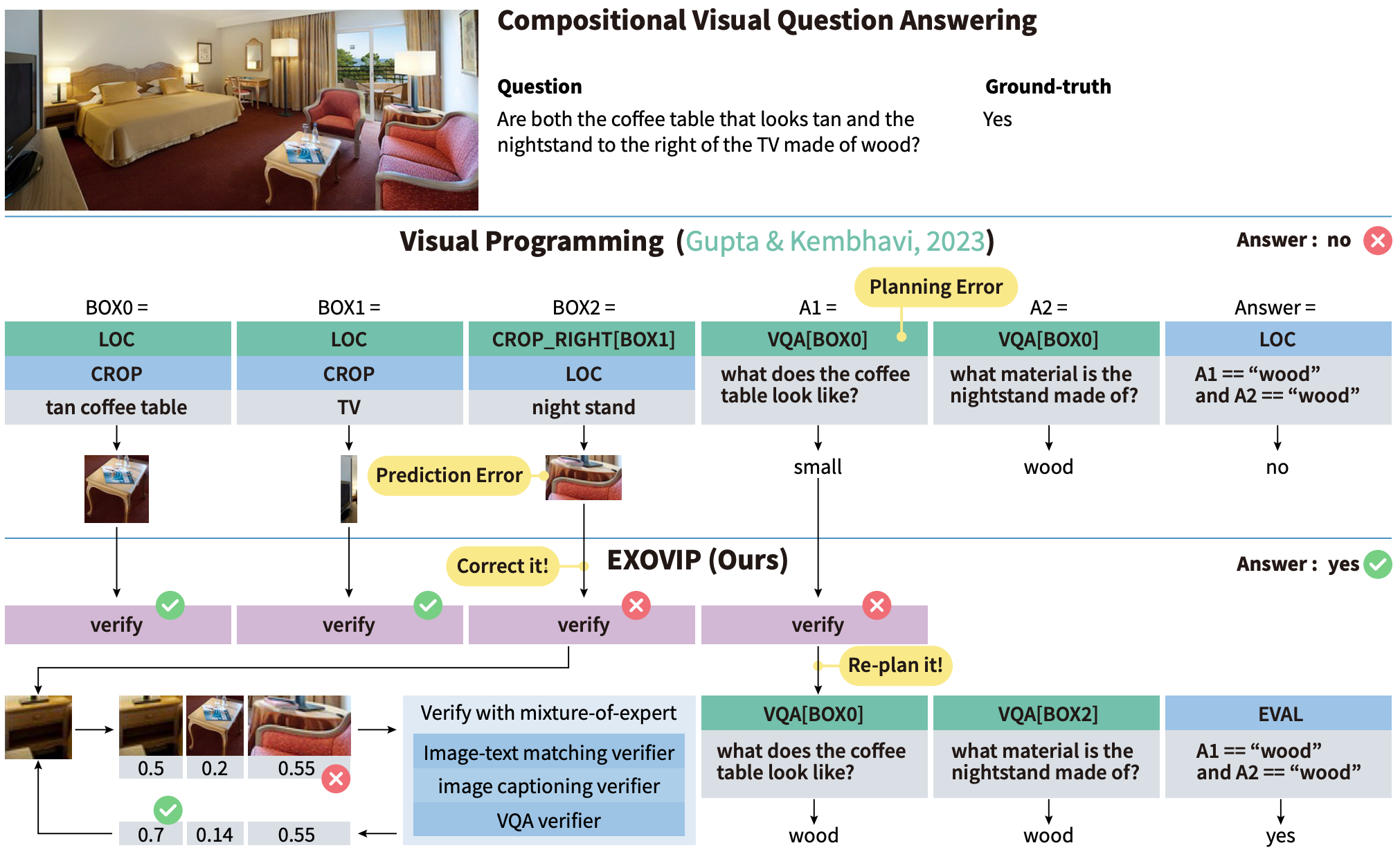
ExoViP: Step-by-step Verification and Exploration with Exoskeleton Modules for Compositional Visual Reasoning
Yuxuan Wang,
Alan Yuille,
Zhuowan Li*,
Zilong Zheng*
COLM, 2024
arXiv /
code
|
|
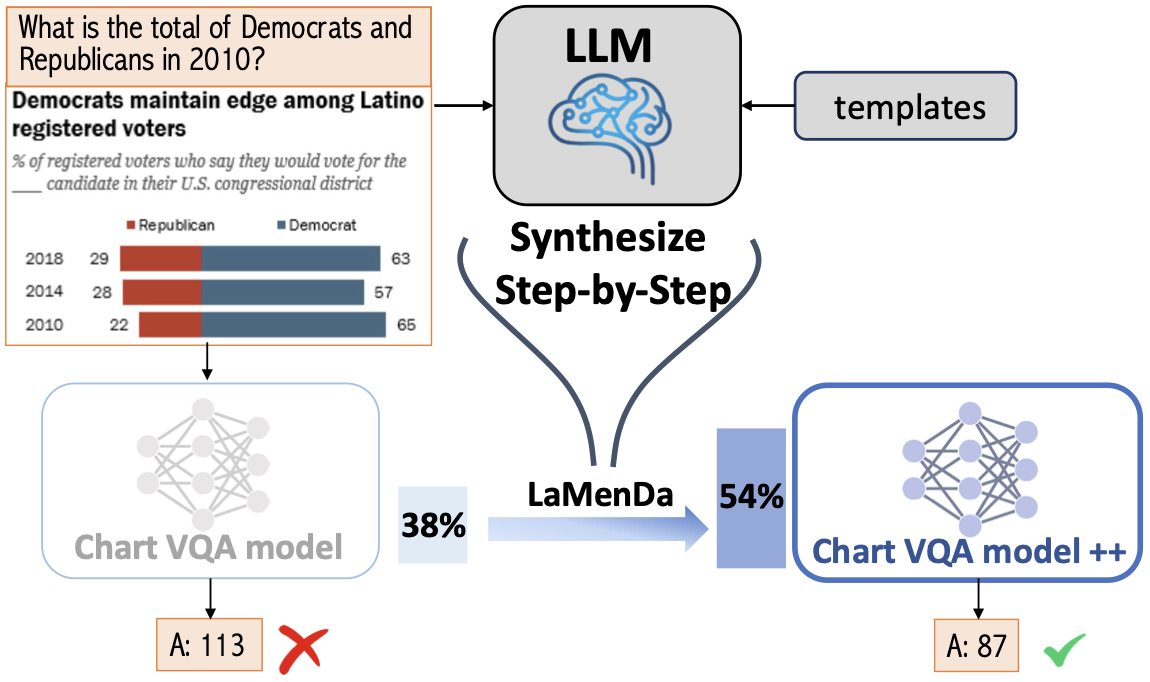
Synthesize Step-by-Step: Tools, Templates and LLMs as Data Generators for Reasoning-Based Chart VQA
Zhuowan Li*,
Bhavan Jasani*,
Peng Tang,
Shabnam Ghadar
CVPR, 2024
arXiv
|

|
Causal-CoG: A Causal-Effect Look at Context Generation for Boosting Multi-modal Language Models
Shitian Zhao,
Zhuowan Li,
Yadong Lu,
Alan Yuille,
Yan Wang
CVPR (Highlight, top 2.8%), 2024
arXiv /
code
|

|
On the Diagnosis and Generalization of Compositional Visual Reasoning
Zhuowan Li
Ph.D. thesis, 2024
pdf
|
|
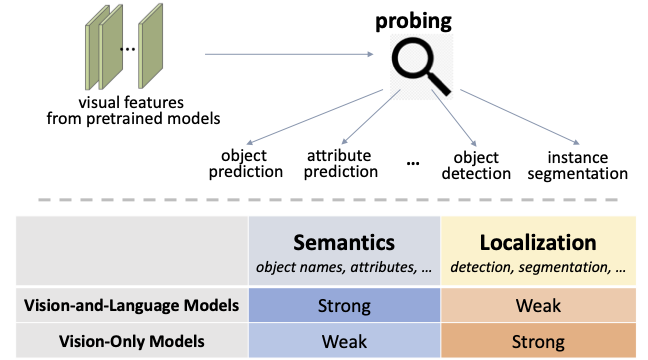
Localization vs. Semantics: How Can Language Benefit Visual Representation Learning?
Zhuowan Li,
Cihang Xie,
Benjamin Van Durme,
Alan Yuille
EACL, 2024
arXiv /
code (to be released)
|

|
3D-Aware Visual Question Answering
about Parts, Poses and Occlusions
Xingrui Wang,
Wufei Ma,
Zhuowan Li,
Adam Kortylewski,
Alan Yuille
NeurIPS, 2023
arXiv /
code and dataset
|
|
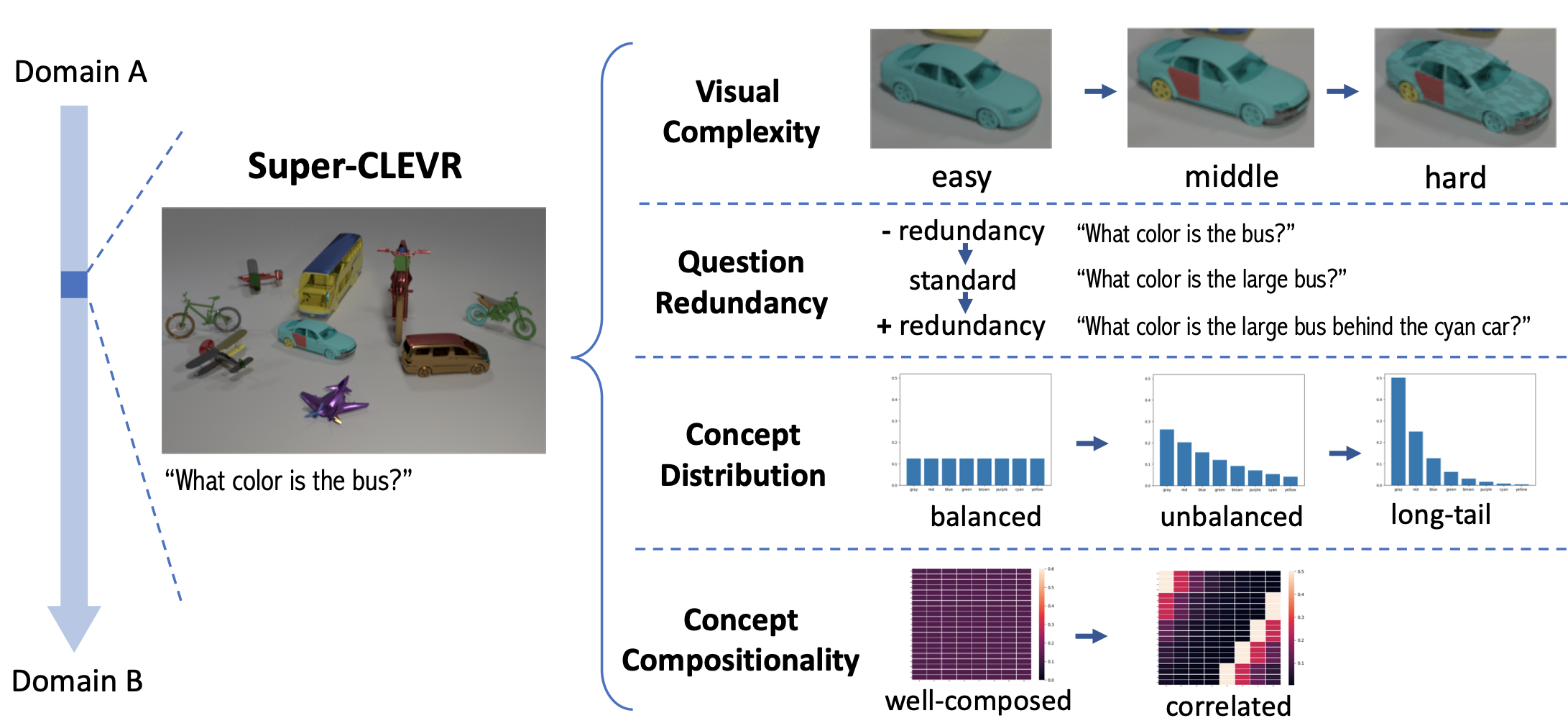
Super-CLEVR: A Virtual Benchmark to Diagnose Domain Robustness in Visual Reasoning
Zhuowan Li,
Xingrui Wang,
Elias Stengel-Eskin,
Adam Kortylewski,
Wufei Ma,
Benjamin Van Durme,
Alan Yuille
CVPR (Highlight, top 2.5%), 2023
project page /
arXiv /
code and dataset
|
|
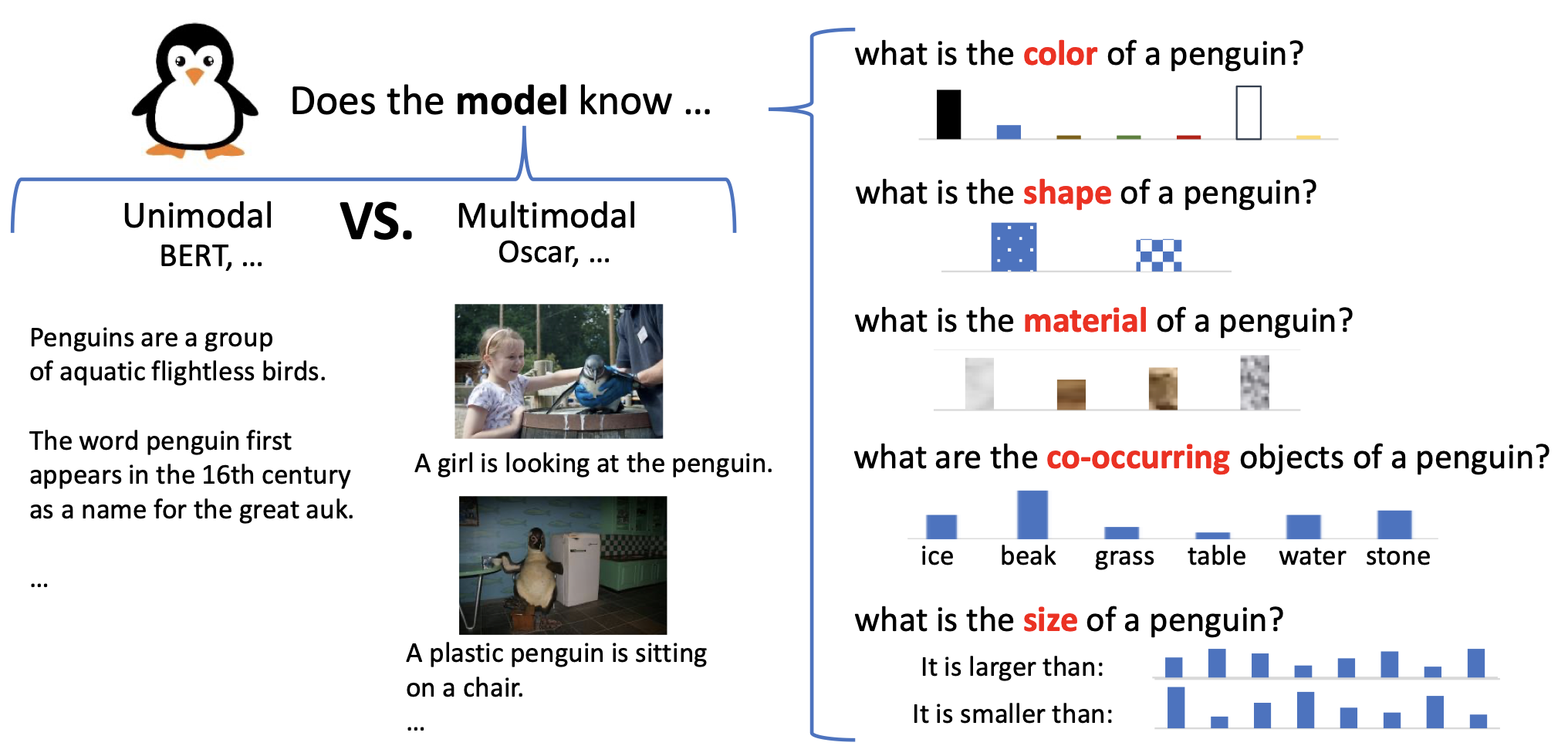
Visual Commonsense in Pretrained Unimodal and Multimodal Models
Chenyu Zhang
Benjamin Van Durme,
Zhuowan Li*,
Elias Stengel-Eskin*,
NAACL (Oral), 2022
arXiv /
code and dataset
|
|
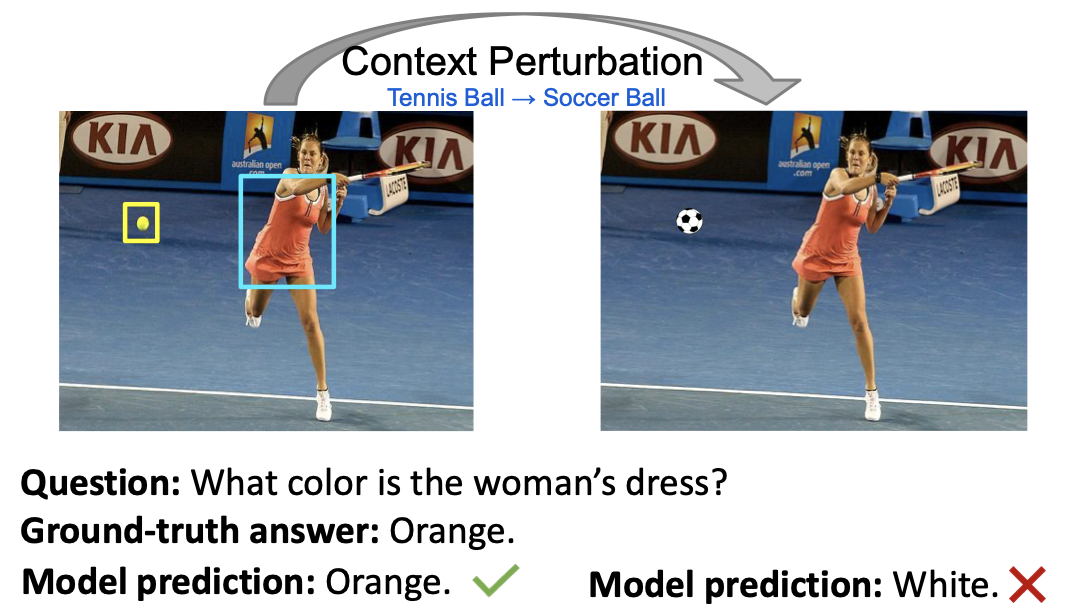
SwapMix: Diagnosing and Regularizing the Over-Reliance on Visual Context in Visual Question Answering
Vipul Gupta,
Zhuowan Li,
Adam Kortylewski,
Chenyu Zhang,
Yingwei Li,
Alan Yuille
CVPR, 2022
arXiv /
code
|
|
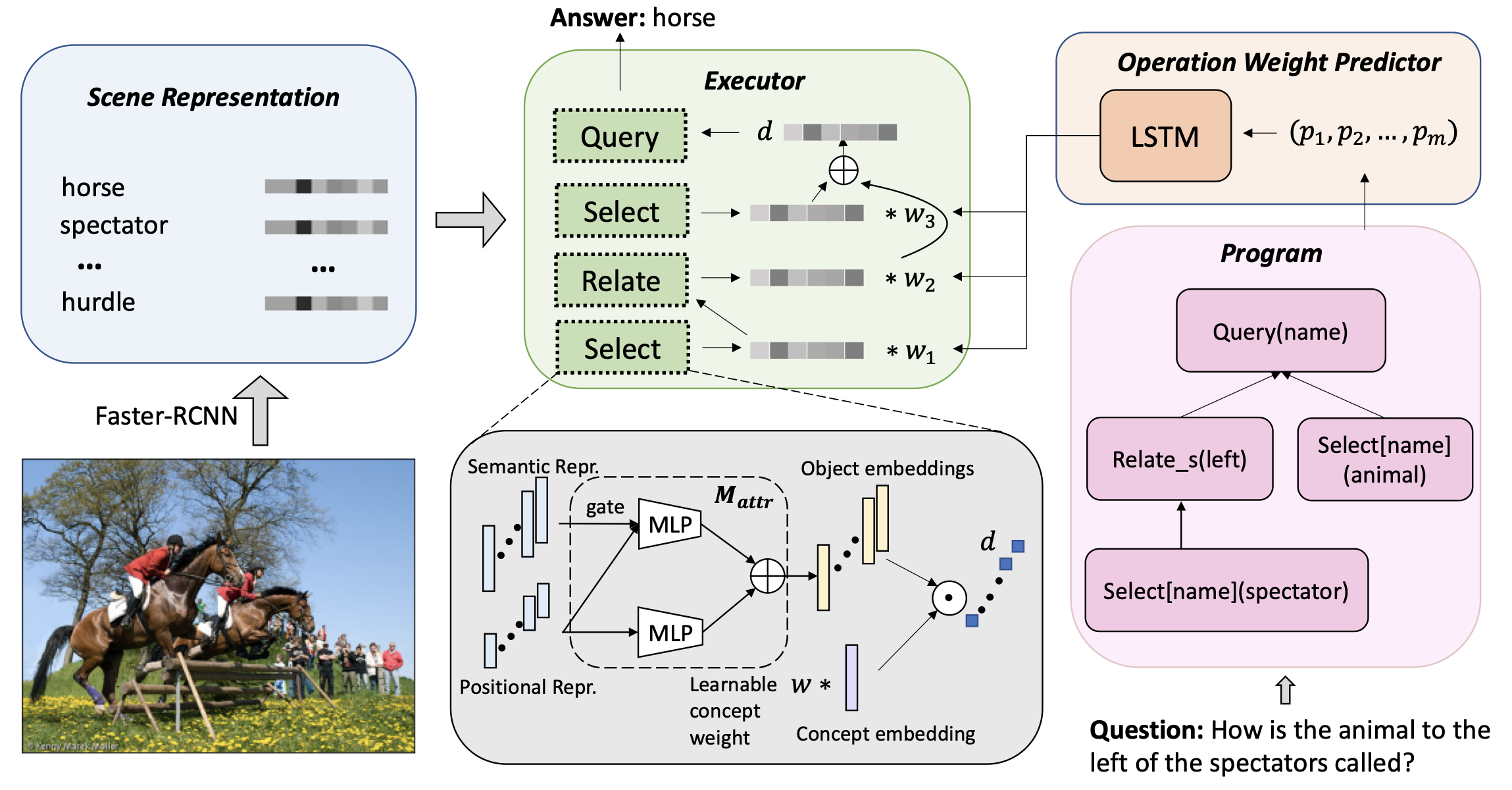
Calibrating Concepts and Operations: Towards Symbolic Reasoning on Real Images
Zhuowan Li,
Elias Stengel-Eskin,
Yixiao Zhang,
Cihang Xie,
Quan Tran,
Benjamin Van Durme,
Alan Yuille
ICCV, 2021
arXiv /
code
|

|
Context-Aware Group Captioning via Self-Attention and Contrastive Features
Zhuowan Li,
Quan Tran,
Long Mai,
Zhe Lin,
Alan Yuille
CVPR, 2020
arXiv /
project page
|
|
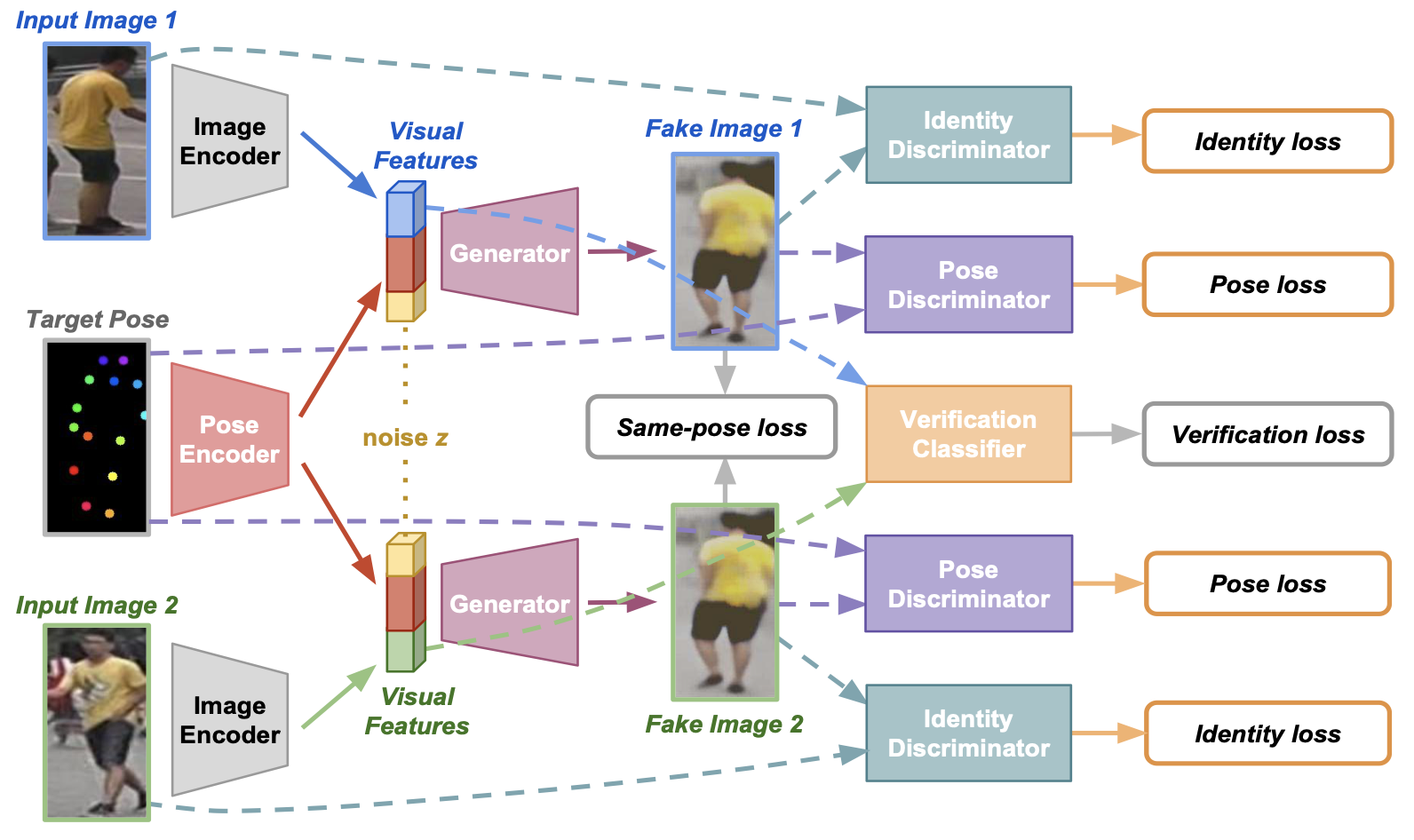
FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification
Yixiao Ge*,
Zhuowan Li*,
Haiyu Zhao,
Guojun Yin,
Shuai Yi,
Xiaogang Wang,
Hongsheng Li
NeurIPS, 2018
arXiv /
project page /
code
|
|